Google I/O 2021, NAVER AI NOW, MS build 2021 요약
여러모로 바쁘고 뒤숭숭한 와중에 온라인 컨퍼런스들이 쏟아지고, 사전 신청을 했지만 할 일이 많아 틈틈이 듣기 힘들었다.
다 요약할 겨를이 없어서 최근 들었던 세가지 컨퍼런스의 간단한 내용 요약 정도로 포스팅을 하려 한다.
Google I/O 2021 (5.18–20)
](https://cdn-images-1.medium.com/max/2000/0*SSWhEemMYd2GcBhg.jpg)
매년 새로운 구글 서비스와 안드로이드 업데이트를 발표하기에 중학생때부터 재밌게 봐왔던 구글I/O. 올해도 작년처럼 온라인으로 진행되었고, 나는 제주도에 있는 와중에 I/O 21까지 실시간으로 듣기는 힘들었다. 서울로 돌아와서 요약된 유튜브 영상이나 정리글들이 많이 올라와서 보는데 이번 I/O 21에서 흥미로운 내용들을 모아서 몇가지 키워드로 정리하면 다음과 같다.
-
대화형 언어 모델 LaMDA : 본인이 명왕성, 종이비행기 등이라 가정하고.. 더욱 자연스러운 대화가 가능해짐
-
Google Maps 업데이트 : virtual street lines, 실내지도 Indoors, 지도 detail 개선, 시간에 따른 POI 추천, Area business
-
Google Photos 업데이트 : Little Patterns, Cinematic Photos
-
Multimodal Model : 이미지, 텍스트, 오디오, 비디오 등. 원하는 장면을 찾아주는 AI.
-
MUM : 복합적인 모델, 검색엔진은 얼마나 더 정교해질 수 있을지 보여줌
-
Android 12 : 개인 맞춤 Material design Material You(개인적으로 디자인 별로)적용, 성능&개인정보보호 개선, Digital car key
-
웨어러블 OS 통합 : Google-Samsung 연합, 30% 속도 향상, 배터리 성능 향상, 올 가을 갤럭시 워치에 탑재 예정
-
Starline : 실제같이 생생한 영상통화, depth센서를 이용한 3D imaging → Real time Compression. 특수장비인 Light Field Display에서 사용 가능.
NAVER AI NOW (5.25)
](https://cdn-images-1.medium.com/max/2400/0*p7Xm5Iy2EVkWGeqQ.png)
25일에는 부서 사람들에게도 아침 스크럼 때 링크를 공유를 해서 이 날은 다 같이 키노트를 시청했는데, 네이버 클로바 CIC에서 HyperCLOVA를 온라인으로 공개하는 장이었다. SNS 광고와 네이버 메인에 배너광고, FB community 등 정말 이곳 저곳에 대대적으로 홍보를 해서인지 컨퍼런스 중간에 실시간 시청자 수가 7만명을 넘는 것을 봤다.
네이버가 AI쪽에 많은 투자와 노력을 하고 있음을 재차 확인할 수 있었다. 왜 굳이 모델을 만드는가?에 대한 해답을 세션 중에 설명하지만 핵심은 이것이다.
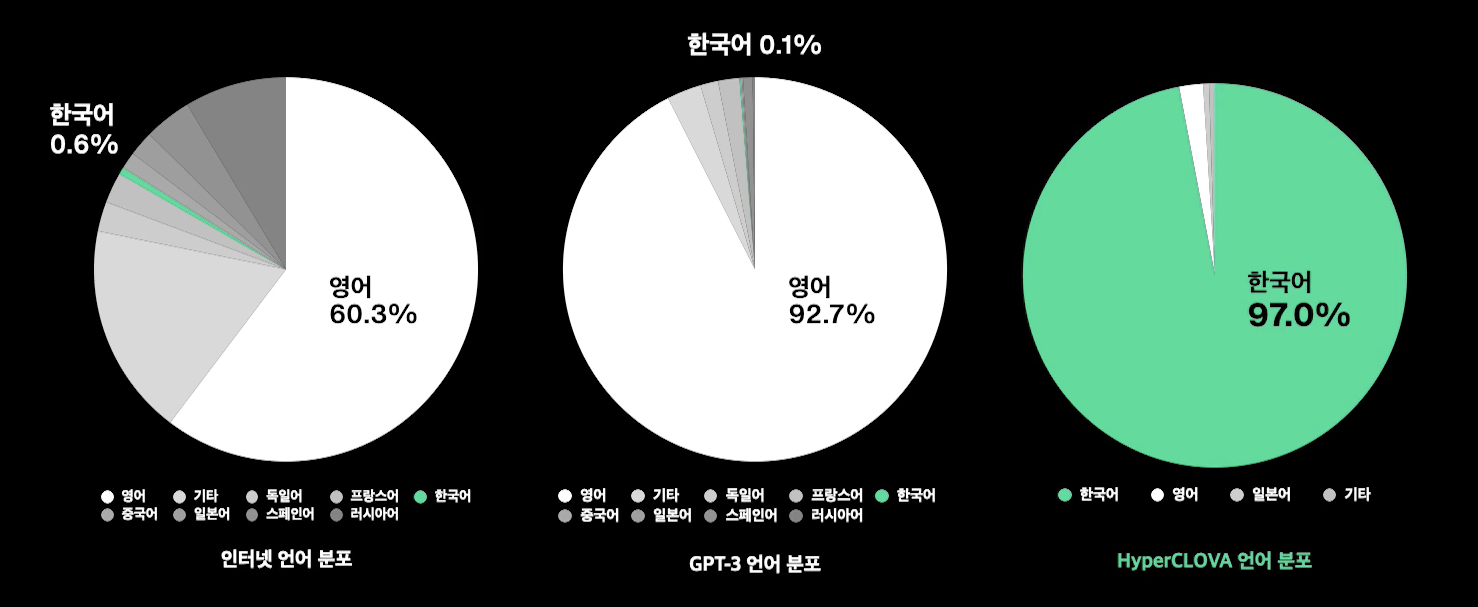
GPT-3에서 한국어의 비중은 0.1% 미만입니다. (중략) 만약 한국어에 맞는 Big Model을 확보하지 못한다면 글로벌 기업들이 강력한 영어 모델을 기반으로 다양한 서비스를 만들어낼 때 우리는 그들이 제공하는 제한적인 한국어 성능의 모델을 사용할 수 밖에 없게되고, 이는 기술이 종속되는 현상 뿐 아니라 한국어 기반 서비스의 성장에 명확한 한계로 작용하게 될 것입니다.
소위 “무식하게 크기를 키우고, 데이터를 때려박은” GPT-3는 여지껏 보지 못했던 놀라운 결과를 보여주고 있고, 다양한 영역에 하나의 모델을 사용하여 해결이 가능하다. 바야흐로 우리는 Big AI의 시대에 접어들고 있다. 이러한 상황 속에서 네이버는 대용량 데이터를 활용해 초대형 한국어 언어 모델을 학습하고 이를 사용할 수 있는 언어 모델을 개발한 것은 필요했고, HyperCLOVA를 통해 AI주권을 확보하고 글로벌 AI 기술 리더로 나아가는 비전을 제시한 것이다.
여튼 초거대 AI ‘HyperCLOVA’를 공개한 이번 AI NOW를 나는
-
대규모의 한국어 데이터를 학습한 ‘최초의 한국어 초거대 언어모델’ HyperCLOVA
-
국내 뿐 아니라 글로벌 AI R&D의 리딩
라는 두가지 중점적인 측면으로 나는 시청했다.
PART1.
새로운 AI의 시작, HyperCLOVA
- 700PF 수퍼컴퓨터, 204B(2,400억) 규모 모델, 한국어 5,600억 토큰(GPT-3 한국어 대비 6,500배)
-
맥락을 이해하고 공감하는 대화 가능 — 자연스러운 연결된 대화 가능
-
창작을 도와주는 글쓰기 — 예시문장 만들기, 상품소개문구 생성
-
정보요약
-
데이터 생성 — AI 개발 프로세스 가속화
- 데이터, 전문성, 시간과 노력 모두 줄임 → 누구나 인공지능 모델을 만들 수 있도록
HyperCLOVA를 위한 슈퍼 컴퓨팅 인프라
-
OCR, AiCall, Chatbot — AI 응용서비스
-
Cloud Platform
-
GPT-3와 같이 대규모 AI의 경우 수백-수천개의 GPU서버를 병렬적으로 사용해야 함
-
국내 최고 성능의 AI연구 슈퍼컴퓨터 이용. 글로벌 TOP 500 List 수준
-
140 computing node, 1120 GPU, 3800 cables
-
고성능 병렬 GPU 클러스터 / 초저지연 고대역폭 네트워크 / 고성능 병렬 아키텍처 스토리지
-
클라우드 인프라 운영 역량 / 데이터센터 구축 노하우 / 모니터링 플랫폼과 운영 자동화
-
네이버 클라우드 플랫폼(180여개 이상의 다양한 클라우드 서비스 중)에서 사용 가능할 예정.
HyperCLOVA를 위한 Big Data
-
다양한 내용, 범용의 구성, 양질의 정보, 충분한 크기 → 이 네가지를 만족하는 좋은 데이터 확보에 노력 : 1.96TB, 한국어 5600억 토큰
-
GPT-3대비 6,500배
새로운 글로벌 AI R&D 리더십
-
공개된 기술 적용 vs 자체 기술 개발
-
글로벌 빅테크 기업들이 공개된 기술을 적용하는 것은 기술 경쟁력 측면에서 한계 → 네이버는 글로벌 AI 리더십 확보를 목표로
-
연구-서비스 선순환 구조(연구 → 엔진 → 프로덕트 → 서비스→data→연구 형태)
-
AI연구가 아카데미에서 회사 중심으로 갈 수 박에 없음. 새로운 산학협력 연구형태가 필요 → 네이버는 새로운 연구협력 생태계를 만들어감
-
국내 기업 중 최대 수치의 AI 논문 수. 발표 논문 중 상당 수가 인턴과 함께.
-
글로벌 AI Research Belt 구축
-
서울대학교 AI 연구원과 ‘서울대-네이버 초대규모 AI 연구센터’를 설립
-
카이스트 AI 대학원과 ‘카이스트-네이버 초창의적 AI 연구센터’ 설립.
AI Ethics: AI, 사람을 위한 일상의 도구
-
네이버 AI 윤리 준칙 : 서울대 AI 정책 이니셔티브(SNU AI Policy Initiative, SAPI) 협업 결과물
-
한글/영문으로 공개
-
‘일상의 도구’가 된다는 것 : CLOVA CareCall, CLOVA 램프
-
학계와 AI 윤리 협업, 스타트업에게도 협력
-
독자적인 AI 윤리원칙 마련, 다양한 AI 이슈에 대한 대응이 가능
PART2.
-
HyperCLOVA의 한국어 모델
-
HyperCLOVA Studio 나에게 필요한 인공지능, 내 손으로 쉽게 만들기
-
HyperCLOVA의 활용 (1) 검색 어플리케이션(Search Applications)
-
HyperCLOVA의 활용 (2) AI 어시스턴트(AI Assistant)
-
HyperCLOVA의 활용 (3) 대화 (Conversation)
-
HyperCLOVA의 활용 (4) 데이터 증강 (Data Augmentation)
-
HyperCLOVA의 조율(Controllability)
-
HyperCLOVA를 위한 서비스 기반 (Service Infrastructure)
이번에 우리 학교에 새로 부임하신 이광형 총장님도 영상으로 Intro에 등장하셔서 축사를 하셨다.
동시에 앞으로 AI를 연구하기 위해서 학교와 기업의 역할에 대한 생각을 했다. 리서치를 기업이 아카데미를 이미 앞서고 있고, 이미 기업에서 몇 년 전에 시도해보고 결과까지 내본 것을 대학원이 뒤따라오고 있는 현실이다. 특히 압도적인 자원(자본)은 덤. 새로운 형태의 산학협력을 말한 것도 그 이유에서 일 것이다.
Microsoft Build 2021 (5.25–27)
](https://cdn-images-1.medium.com/max/2400/0*K2thoUbl7JzBAdw0.png)
이번 Microsoft Build 2021에서는 ‘차세대 기술과 하이브리드 업무의 미래’를 주제로 하이브리드 시대의 생산적인 솔루션 개발을 위한 개발자 툴과 플랫폼 등 최신 기술 동향을 보여주었다. 테크니컬 세션, 러닝존, 커넥션존, 로컬 커넥션 존 등이 있었으나, 나는 나중에 영상으로만 확인. 100개 이상의 서비스에서 업데이트를 다루고 있기에 전체 세션을 다 시청하고 정리하기에는 분량이 방대해, 내 마음대로 선정한 세션들만 정리를 해본다.
Power Apps
-
No code. OpenAI사의 GPT-3를 적용 → Tranform natural language in to code
-
Power Fx for Model Driven Apps
-
Industry components
-
Power Apps Developer plan
Microsoft Teams
-
Collaborative Apps
-
Fluid components in Teams chat
-
공유 스테이지 통합 기능, 신규 미팅 이벤트 API
-
Together mode : 가상화면에 모일 때
-
Teams Toolkit
Azure
-
Azure Arc / Azure Functions / Azure Logic Apps
-
Azure ML
-
Bot Framework Composer 2.0
-
Azure Metrics Advisor, Azure Video Analyser …
Comments